リアルタイム最適化チェックリスト|計測から始める実践ガイド

「ポリゴン数を減らせば軽くなる」という素朴な信念は、しばしば外れます。実機で重いのが GPU か CPU かを見ていないと、削っても削っても改善しない、という消耗戦が始まるからです。最適化は 計測から始める が大原則。本記事では、ボトルネックの4分類・アセット種別ごとの最適化アプローチ・計測ツールの使い分け・ジャンル別の優先順位を、現場で「で、どこから手をつける?」と聞かれたときに即答できる粒度で整理します。
 夕宮たいだ
夕宮たいだふぁ……みんな〜、最適化って最初みんな迷うんだぁ。「とりあえずポリゴン減らそ」じゃなくて、「どこが重いか見る」から始めるのが大事なんだよぉ。一緒に整理していこ〜。
1. なぜ最適化が必要なのか
ひとことで:フレームレート目標とプラットフォーム性能の差を埋めるための工程です。
リアルタイム描画では、目標 FPS(Frames Per Second=1秒あたりに何枚の画面を描画できるか。30/60/120 などが代表値)に対して1フレームあたりの予算時間が決まります。60 FPS なら 1フレーム 16.67ms(ミリ秒)以内、30 FPS なら 33.3ms 以内。この予算を超えるとフレーム落ち(カクつき)が発生します。最適化はこの予算を守るための工程です。
予算は CPU と GPU の両方で別々に守る必要があります。CPU で 20ms、GPU で 5ms かかっていれば、フレーム時間は 長い方 に引きずられて 20ms(=50FPS)になります。両方を同時に縮める発想が必要です。
「計測なしの最適化はやらない」が大原則
実機での重さは、推測と実測がしばしば食い違います。「重そう」な処理が実は軽く、「軽いはず」が重いのは日常茶飯事で、計測なしで作業を始めると当たらないところを延々と削る ことになります。順序は「①目標FPSと予算を決める → ②実機で計測 → ③ボトルネックを特定 → ④該当箇所だけ改善」。この順序を崩さないでください。
 夕宮たいだ
夕宮たいだ推測で削っちゃダメ、絶対! 「重そう」と「重い」は別物なんだぁ。Profiler 回してから、削るとこ決めようねぇ。
2. 最適化の全体像:CPU・GPU・メモリ・帯域
ひとことで:ボトルネックは大きく4種類あり、対処法がそれぞれ異なります。
下図のように、リアルタイム描画のボトルネックは次の4分類で考えると整理しやすいです。
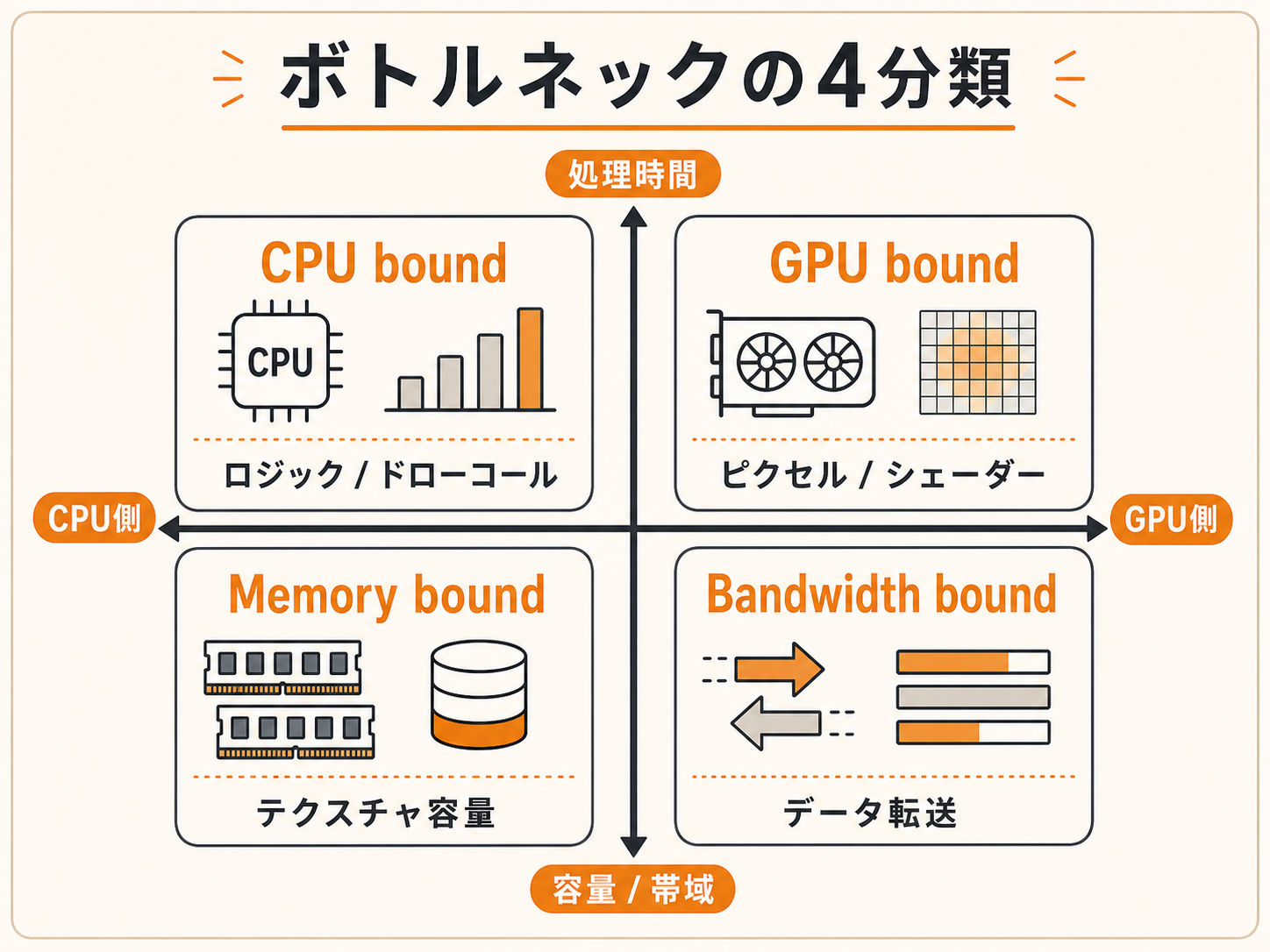
| 分類 | 何が遅い | 主な原因 | 対処の方向 |
|---|---|---|---|
| CPU bound | CPU処理 | ゲームロジック、ドローコール準備、AI、物理 | バッチング、ロジック軽量化、マルチスレッド化 |
| GPU bound | GPU描画 | ピクセル数、シェーダー命令、オーバードロー | LOD、シェーダー簡略化、解像度調整 |
| Memory bound | メモリ容量 | 高解像度テクスチャ、未圧縮アセット | 圧縮、解像度ダウン、ストリーミング |
| Bandwidth bound | メモリ帯域 | テクスチャ読み込み量、頂点読み込み量 | 圧縮、データ量削減、キャッシュ意識 |
CPU bound と GPU bound はフレーム時間(ms)に直接効きます。Memory / Bandwidth は容量・転送量の話で、超過するとフレーム時間にも波及します。実機で計測すると、Profiler 上に「CPU フレーム時間」と「GPU フレーム時間」が並んで表示されます。長い方が現在のボトルネック で、明らかに片方が長ければ、長い方だけを削ります。
3. メッシュ系:ポリゴン数・LOD・頂点バッファ
ひとことで:ポリゴン数だけでなく、LODとドローコールまで含めて最適化します。
メッシュ系の最適化は、最も歴史が古く、誤解も多い領域です。
ポリゴンバジェットの感覚値
プラットフォームと描画範囲によって正解は変わりますが、感覚値の目安は以下です。
| プラットフォーム | 1キャラの目安 | 1シーン全体の目安 |
|---|---|---|
| ハイエンドPC / コンソール | 30,000〜100,000 ポリゴン | 数百万〜千万単位 |
| Switch / 中堅モバイル | 10,000〜30,000 ポリゴン | 数十万〜数百万 |
| ローエンドモバイル | 3,000〜10,000 ポリゴン | 数十万 |
「ポリゴン数の上限」より、画面占有率に対する密度 で考えるのが本質です。画面の数ピクセルしか占めない遠景に高ポリゴンは無駄、画面いっぱいの主人公にローポリは破綻、と用途で割り当てます。
LOD:距離別の差し替え
LOD(Level of Detail)は、カメラからの距離に応じてポリゴン数の異なるメッシュに差し替える仕組みです。一般に 3〜4段階 を用意します。
- LOD0:原寸。ポリゴン数100%
- LOD1:中距離。50%程度
- LOD2:遠距離。25%程度
- LOD3:超遠距離 or インポスター(Impostor=3Dの代わりに2D看板で表示する手法。遠景の木や群衆で頻用)。5〜10%
LOD 切り替え時のポップ(見た目の急変)を抑えるには、エンジンの Dither フェード や Cross-fade LOD を有効にします。背景アセットには LOD が必須、キャラ・主要プロップは LOD0/1 だけでも回ります。

ドローコールとバッチング
ドローコール(Draw Call)は、CPU が GPU に「これを描画して」と指示する1回分です。1フレームあたりのドローコール数は CPU 負荷の主要因で、ハイエンドで 5,000〜10,000、モバイルで 100〜500 が現実的な目安です。削減手段は バッチング:
- Static Batching:静止オブジェクトを統合
- Dynamic Batching:動くオブジェクトを統合(条件あり)
- GPU Instancing(GPUインスタンシング:同じメッシュをパラメータ違いで多数描画するときに使う仕組み。草・群衆の表現で必須):同じメッシュを多数描画する場合、1コールで一括処理
同じマテリアル・同じメッシュを使い回す設計がバッチングを効かせる鍵で、背景アセットは特にマテリアル数を絞る意識が効きます。
ていねいに整理するねぇ。ポリゴン削るより、ドローコール減らす方が効くこと、けっこうあるんだぁ。同じマテリアル使い回す設計、地味に大事だよぉ。
4. テクスチャ系:解像度・圧縮・アトラス
ひとことで:解像度・圧縮形式・アトラス化の3点で、メモリと帯域の両方に効きます。
テクスチャ最適化は、メモリと帯域の両方に効く領域です。
解像度設計
テクスチャは画面占有率と物理サイズに見合う解像度で十分です。手のひらサイズの小道具に 4K テクスチャを貼っても、画面に映る数ピクセルでは違いが見えません。一般的な目安は次のとおりです。
- キャラの主要パーツ:1024〜2048 px
- 背景の主要オブジェクト:1024 px
- 小物・遠景:256〜512 px
- UI:必要解像度ぎりぎり
「テクセル密度」(ワールド空間1単位あたりのテクセル数)を揃える設計は CR-03 UVとテクセル密度の設計 で扱いました。
圧縮形式
GPU で扱うテクスチャは、ほぼ必ず圧縮形式に変換します。BC1〜BC7 / ASTC の使い分けは CR-05 チャンネルパッキング戦略 で詳しく扱いました。要点だけ再掲すると、カラーは BC1 / 透過付きカラーは BC3 or BC7 / ノーマルは BC5 / パックドは BC7 / モバイルは ASTC です。未圧縮 PNG/TGA をそのままビルドに含めるのは厳禁です(容量が10〜20倍)。
アトラス化
アトラス(Atlas)は、複数のテクスチャを1枚に詰め込んで管理する手法です。ドローコール削減(同じマテリアルを共有しやすくなる)と、テクスチャサンプル数削減の両方に効きます。
UI、エフェクト、葉っぱや小物のような小さい絵柄は、アトラスにまとめるとパフォーマンスが大きく改善します。逆にキャラのような大物テクスチャは、アトラス化のメリットが薄く、独立で持つほうが管理しやすいです。
Mipmap
Mipmap は、距離に応じてテクスチャの低解像度版を自動切り替えする仕組みです。3Dテクスチャでは原則オン。オフにすると遠景のちらつきとメモリアクセスの非効率が起きます。UI など視点距離が固定の場合のみオフが妥当です。
5. シェーダー系:命令数・分岐・バリアント
ひとことで:命令数・分岐コスト・バリアント爆発の3つで、GPU負荷とビルド時間に直接効きます。
シェーダーは、書き方ひとつで GPU 負荷が大きく変わる領域です。
命令数の目安
ピクセルシェーダーの命令数は GPU 負荷に直結します。エンジン側に「シェーダー命令数」「テクスチャサンプル数」を表示する機能があるので、まずそれで現状を把握します。複雑なノードグラフのまま放置すると簡単に300〜500命令を超えるので、50〜150命令を目安に節約できる箇所を見直します。
分岐(if)のコスト
GPU は「同じ命令を多数のピクセルに並列で実行する」アーキテクチャです。if で分岐すると、両方の経路を実行してから結果を選ぶ場合があり、純粋に1命令で済まないことがしばしばあります。
実用上の指針は 「分岐は静的(コンパイル時に決まる)にする」。マテリアルの bool パラメータで分岐するなら、Static Switch(UE)/ Shader Variant(Unity)に置き換えてバリアント分割した方が高速です。動的な分岐は、step() や lerp() で表現できないか先に検討します。
シェーダーバリアント爆発
「Static Switch を増やせば速くなる」と思って bool オプションを増やすと、バリアント数が指数的に増えます。下図のように、bool オプションが3つあれば 2³=8 個のバリアント、5つなら 32 個。これがマテリアル全体に掛け算で効くので、ビルド時のコンパイル時間が爆発し、ストレージ容量も膨らみます。
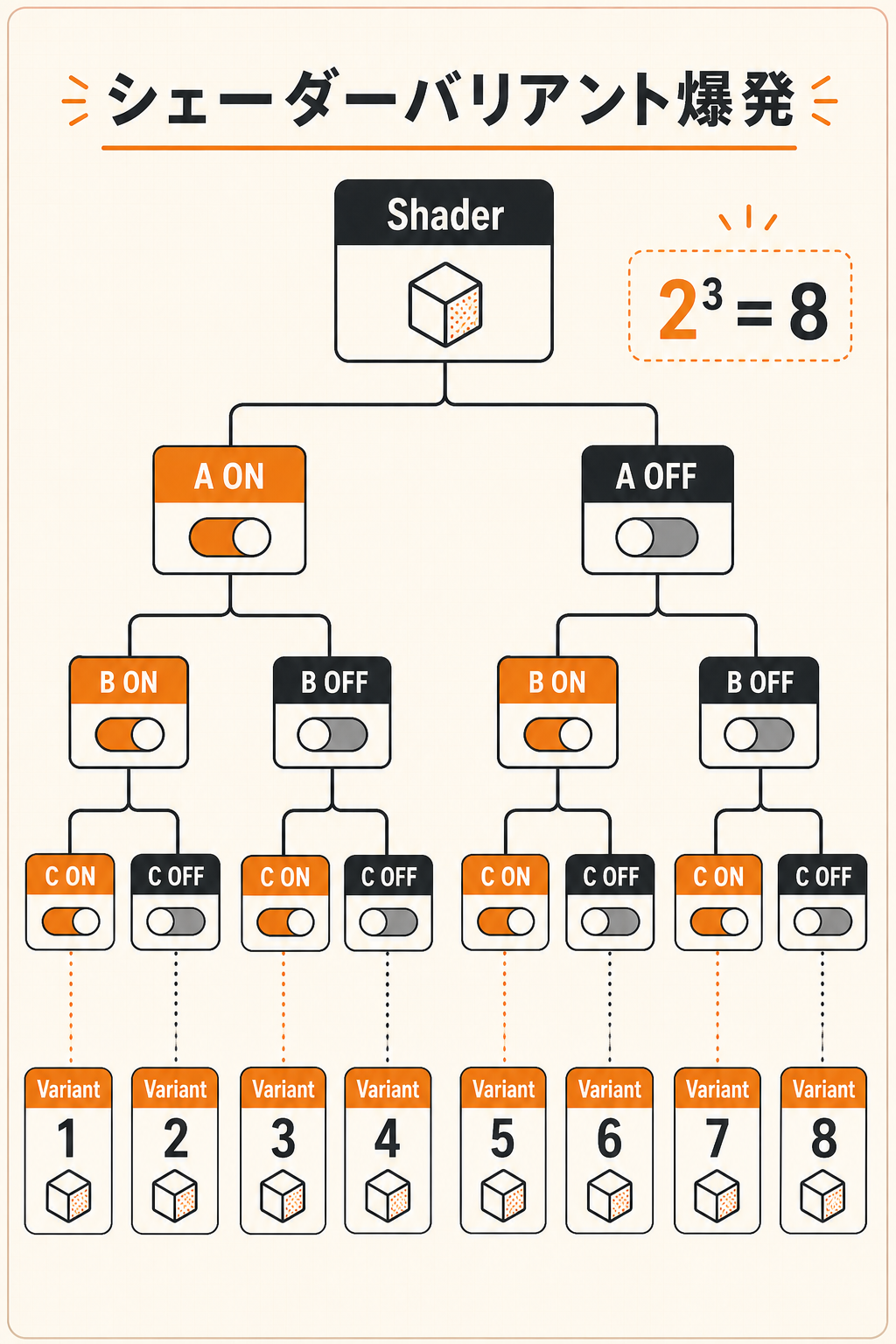
オプションは「本当に必要な切り替え」だけに絞り、似た用途は1つに統合します。
計算をピクセルからバーテックスへ
ピクセルシェーダーは画面上の全ピクセル分実行されますが、バーテックスシェーダーは頂点数分しか実行されません。頂点数 << ピクセル数 が普通なので、ピクセルでなく頂点で計算できる項目(例:UV のスクロール、頂点カラーによる色変化)は、バーテックスに移すだけで負荷が一気に下がります。
 夕宮たいだ
夕宮たいだうぐぅ……バリアント爆発、むずかしいねぇ。便利そうだから bool 増やしまくると、ビルドが何時間も終わらなくなるんだぁ。「本当に必要な切り替え」だけに絞ろうねぇ。
6. ライティング系:ライト数・影・GI
ひとことで:動的ライト数とシャドウ解像度を、シーン規模に見合う数に絞ります。
ライティングはアートの印象を支配する領域ですが、動的に処理すると一気に重くなります。
動的ライト数の制限
動的ライト(Movable / リアルタイム影付き)は、影を毎フレーム生成するため非常に重い処理です。現実的な上限は ハイエンドPC/コンソールで画面内10個程度、モバイルで2〜3個 が目安。それ以上の光源は ライトマップにベイク するか プローブで簡略化 し、動かないライトは静的ライト(Stationary / Static)に降ろすだけで負荷が大幅に下がります。
シャドウマップ解像度
動的影はシャドウマップ(影専用の深度テクスチャ)を毎フレーム生成します。解像度を上げると品質は上がりますが、生成コストとメモリが直線的に増えます。
メインキャラに 2048〜4096 px、サブキャラに 1024 px、動的小物に 512 px、のように 重要度に応じた階層化 が定石です。
ライトマップ vs プローブ
- ライトマップ:静的オブジェクトの間接光をテクスチャに焼き込む。クオリティ高、容量大
- プローブ(Light Probe):空間の点ごとに光情報を保持。動的オブジェクトに適用、容量小
「動かない床・壁=ライトマップ」「歩き回るキャラ=プローブ」が基本配分です。詳細は CR-13 ライティング基礎 で扱います。
7. 計測ツール:UE Insights・Unity Profiler・RenderDoc
ひとことで:エンジン標準のProfilerで全体像を、RenderDocでGPU側の詳細を見ます。
下図のような Profiler 画面を見たことがない方は、まず一度回してみることを強く推奨します。何が重いかが「予想と違う」ことを必ず体験できます。
Unreal Engine Insights
UE 5 標準の総合 Profiler。CPU タイミング・GPU タイミング・メモリ使用量・ロード時間まで一括で見えます。Stat Unit(フレーム時間内訳)と Stat GPU(GPUパス別時間)から始めるのが入口です。
Unity Profiler
Unity 標準。CPU / GPU / Memory / Rendering / Audio など複数モジュールを同時計測できます。Frame Debugger と組み合わせるとドローコール単位の追跡も可能です。
RenderDoc
エンジン非依存の GPU フレームキャプチャツール。1フレームを完全にキャプチャして、ドローコール単位でステート・テクスチャ・シェーダーを確認できます。GPU側の細かい挙動を追うときの定番です。
使い分け
- 全体像を見たい / フレーム時間が予算を超えているか確認 → エンジン標準 Profiler
- 特定のドローコールが何を描画しているか追跡 → Frame Debugger / RenderDoc
- シェーダーの実際の命令数を確認 → エンジン標準のシェーダー詳細表示
ボトルネックの種別判定は、まず Profiler の CPU/GPU フレーム時間を比較することから始めます。
 夕宮たいだ
夕宮たいだほえ〜、Profiler 開くと、こんなに細かく見えるんだぁ。「思ってたのと違う場所が重い」って気づき、最初みんなビックリするんだよぉ。
8. ジャンル別の優先順位
ひとことで:ジャンルによってボトルネックの傾向が決まっており、優先順位が変わります。
下図のように、ジャンルごとに重くなりがちな領域は概ね決まっています。
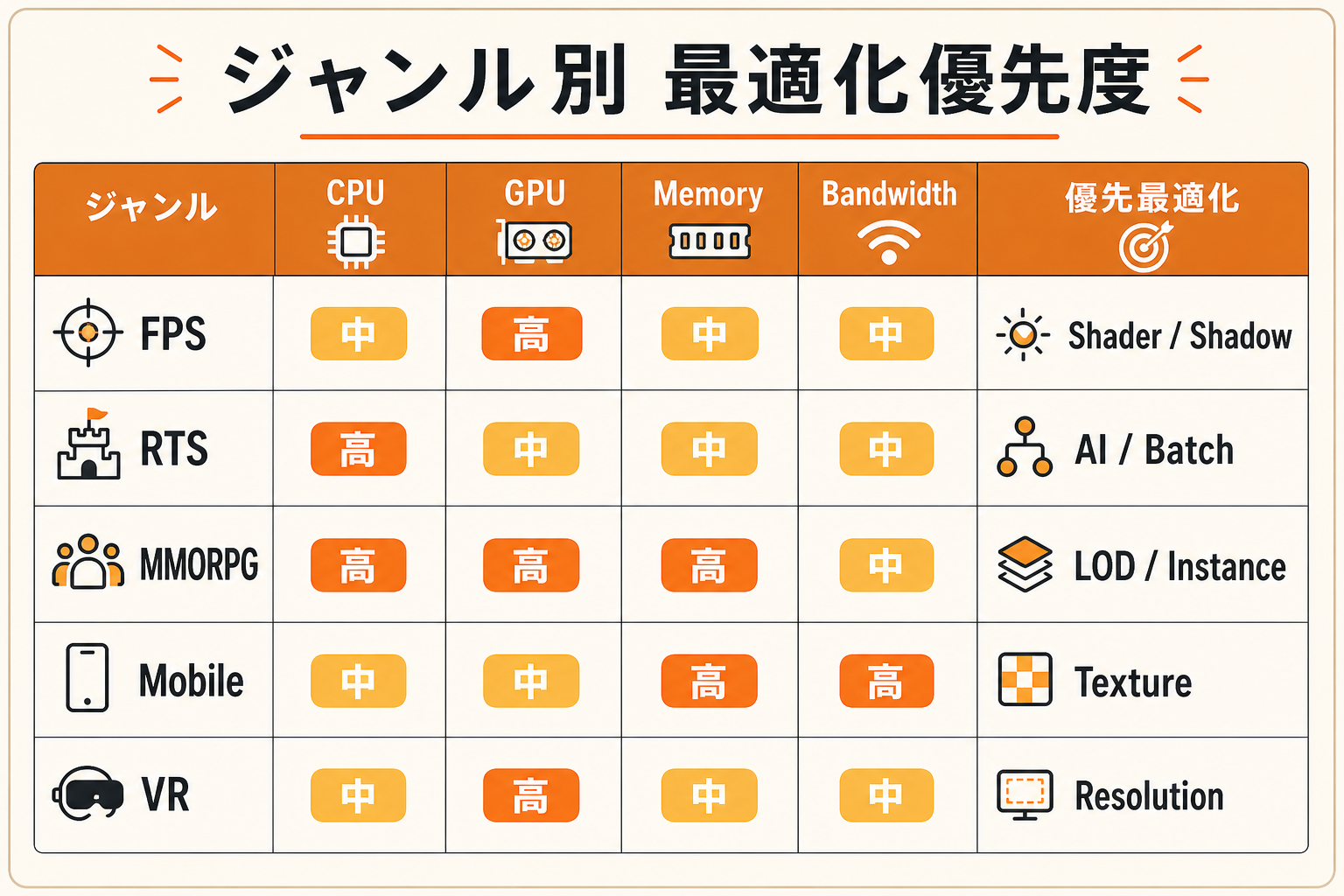
| ジャンル | 主なボトルネック | 優先する最適化 |
|---|---|---|
| FPS / アクション(ハイエンド) | GPU bound | シェーダー、ポストエフェクト、シャドウ |
| RTS / シミュレーション | CPU bound | AI、物理、ドローコール、バッチング |
| MMORPG | CPU + GPU 両方 | キャラ多数前提、LOD・インスタンシング |
| モバイル / Switch | 帯域・メモリ | テクスチャ圧縮、ドローコール、ライト数 |
| VR | GPU bound(両眼で2倍) | 解像度、シェーダー、フォービエイテッド(Foveated Rendering:視点の中心は高解像度、周辺は低解像度で描画する手法) |
「うちのジャンルがどこで詰まりやすいか」を最初に把握すると、最適化の打ち手が早まります。たとえば RTS でポリゴン削減に時間をかけても、CPU bound が原因なら効果は限定的です。
 夕宮たいだ
夕宮たいだほら、自分のジャンル、どこ重くなりやすいか把握しとくと強いよぉ。FPS と RTS で削るべきとこ、ぜんぜん違うんだぁ。
9. ハンズオン演習
ひとことで:実プロジェクトで Profiler を1回回して、ボトルネックを推定します。
1. 計測対象シーンを実機(または開発機)で再生 2. エンジン標準 Profiler を開く(UE:Stat Unit Stat GPU / Unity:Profiler ウィンドウ) 3. CPU フレーム時間 と GPU フレーム時間 を比較 4. 長い方がボトルネック → さらに内訳を見る
- CPU bound なら:ドローコール数、ロジック処理、物理・AIの時間
- GPU bound なら:ベース描画/シャドウ/ポストの時間配分
5. 上位3項目を特定し、本記事の対応する章に戻って打ち手を検討
最初の1回で「想像と違う場所が重い」気づきがあるはずです。これだけで以降の最適化作業が 当たる ようになります。
10. チェックリスト
ひとことで:プロジェクト初期と中盤で確認すべき項目です。
- [ ] 目標 FPS と各プラットフォームの予算時間(ms)が合意されている
- [ ] CPU と GPU のフレーム時間を Profiler で計測する習慣がある
- [ ] LOD が背景アセットに設定されている(3〜4段)
- [ ] ドローコール数の上限と現状値を把握している
- [ ] テクスチャは GPU 圧縮形式(BC / ASTC)に変換されている
- [ ] ノーマルマップは BC5、パックドは BC7(モバイルは ASTC)に設定済み
- [ ] Mipmap が3Dテクスチャでオンになっている
- [ ] シェーダー命令数とサンプル数を主要マテリアルで確認した
- [ ] 動的ライト数がプラットフォーム上限内に収まっている
- [ ] ライトマップ/プローブの使い分けが明確になっている
11. よくある間違い・トラブルシュート
ひとことで:推測で削る・計測しない・1箇所だけ見る、が定番の失敗パターンです。
推測で最適化を始める
「ポリゴン多そうだから削ろう」で工数を費やした結果、CPU bound だったので効果が出ない、というのは最頻出の事故です。Profiler を回す前に削る作業を始めない ルールにします。
LOD が設定されていない
「LOD0だけで運用」しているプロジェクトは、遠景で大量の高ポリゴンメッシュを描画してしまいます。背景の主要アセットには必ず LOD を設定し、エンジンの自動 LOD 機能(UE:Auto LOD、Unity:LOD Group)を活用します。
未圧縮テクスチャが残っている
Texture Importer の圧縮設定を確認せずビルドすると、未圧縮 RGBA8 でビルドに含まれて容量が膨れます。インポート時のデフォルト設定を 必ず GPU 圧縮形式(BC/ASTC) に変えてください。チームで共有するインポーター設定ファイルを置くのが理想です。
動的ライトを置きすぎる
シーン全体で動的ライトを20個以上置いて重くなる、というパターンも頻発します。「動かないライトは Static / Stationary に降ろす」「画面内動的ライトは数個に抑える」を運用ルールにします。
1箇所だけ見て満足する
「シェーダーを軽くしたら数fps改善した」で止めてしまうと、別のボトルネックが温存されて目標 FPS に届きません。最適化は1パスでは終わらない が前提で、計測 → 改善 → 再計測 を3〜5周回す予算で組みます。
夕宮たいだふぁ……最適化の全体像、これでだいたい OK ……かなぁ。「計測 → 削る → また計測」の繰り返しが基本だよぉ。地味だけど、効くんだぁ。
12. 次に読む記事
ひとことで:最適化の各論と、レビュー設計まで進みましょう。
- CR-05 チャンネルパッキング戦略:テクスチャ容量・サンプル数削減の設計
- CR-13 ライティング基礎:ライト・影・GI(Global Illumination=間接光)のベイク/プローブ運用
- CR-14 レビュー・QAの設計:パフォーマンス基準を含むレビュー体制の組み立て
- CR-10 Pythonで横断パイプライン:パフォーマンス基準を機械的にチェックする自動化







