Pythonで横断パイプライン|Maya/Houdini/Painterを繋ぐ設計

自社パイプラインを整備する立場になると、Maya・Houdini・Substance Painter といった複数 DCC を 外側から束ねるスクリプト が必要になります。ボタン1つでアセットを書き出して命名・UV・ヒストリーをチェックし、別 DCC でテクスチャを焼き、エンジンに投げる──こうした横断処理の現代的な共通言語が Python です。
本記事では、各 DCC の Python API(プログラムから機能を呼び出す窓口)の構造、設計パターン3種(Standalone Service / GUI Plugin / Hook)、データ受け渡し方式、テスト・運用、そして「マルチ DCC バリデーター(複数のソフトを横断してデータを検証する仕組み)」の簡易事例までを、TA(テクニカルアーティスト)・テクニカルディレクター視点で整理します。前提として USD 入門(CR-08) や CR-09 アセット命名・バージョン規則 を読んでおくと、本記事の文脈が立体的になります。
 夕宮たいだ
夕宮たいだふぁ……みんな〜、今日はパイプラインのおはなしだよぉ。ちょっと長くなるけどぁ、TA を目指す人には絶対に役立つはずだから、いっしょにいこ〜。
1. なぜパイプラインに Python なのか
ひとことで:DCC共通の言語として、ライブラリ・コミュニティ・採用実績が圧倒的だからです。
パイプライン構築言語の選択肢には、Bash、PowerShell、C#、Go なども考えられます。それでも Python が圧倒的に選ばれる理由は次のとおりです。
- ほぼすべての DCC が Python を 公式サポート している(Maya / Houdini / Painter / Blender / 3ds Max / Nuke)
- ライブラリエコシステムが豊富(PyYAML / requests / pytest / sqlalchemy / fastapi)
- TA・パイプライン界隈の事例公開が多く、検索で正解にたどり着きやすい
- 動的型付け・短いコード・速い試作で、現場の即興と相性が良い
ただし、Python の「動的・短い」ゆえの落とし穴(型の取り違え、依存衝突、バージョン分断)も同時に持ち込みます。本記事はその落とし穴を、設計と運用で減らすことに重点を置きます。
2. 各DCCの Python API 俯瞰
ひとことで:DCCごとにAPI階層と思想が違うので、抽象度を意識して使い分けます。
各 DCC の Python API 階層を、下図のように整理しておくと、後の設計判断がブレません。
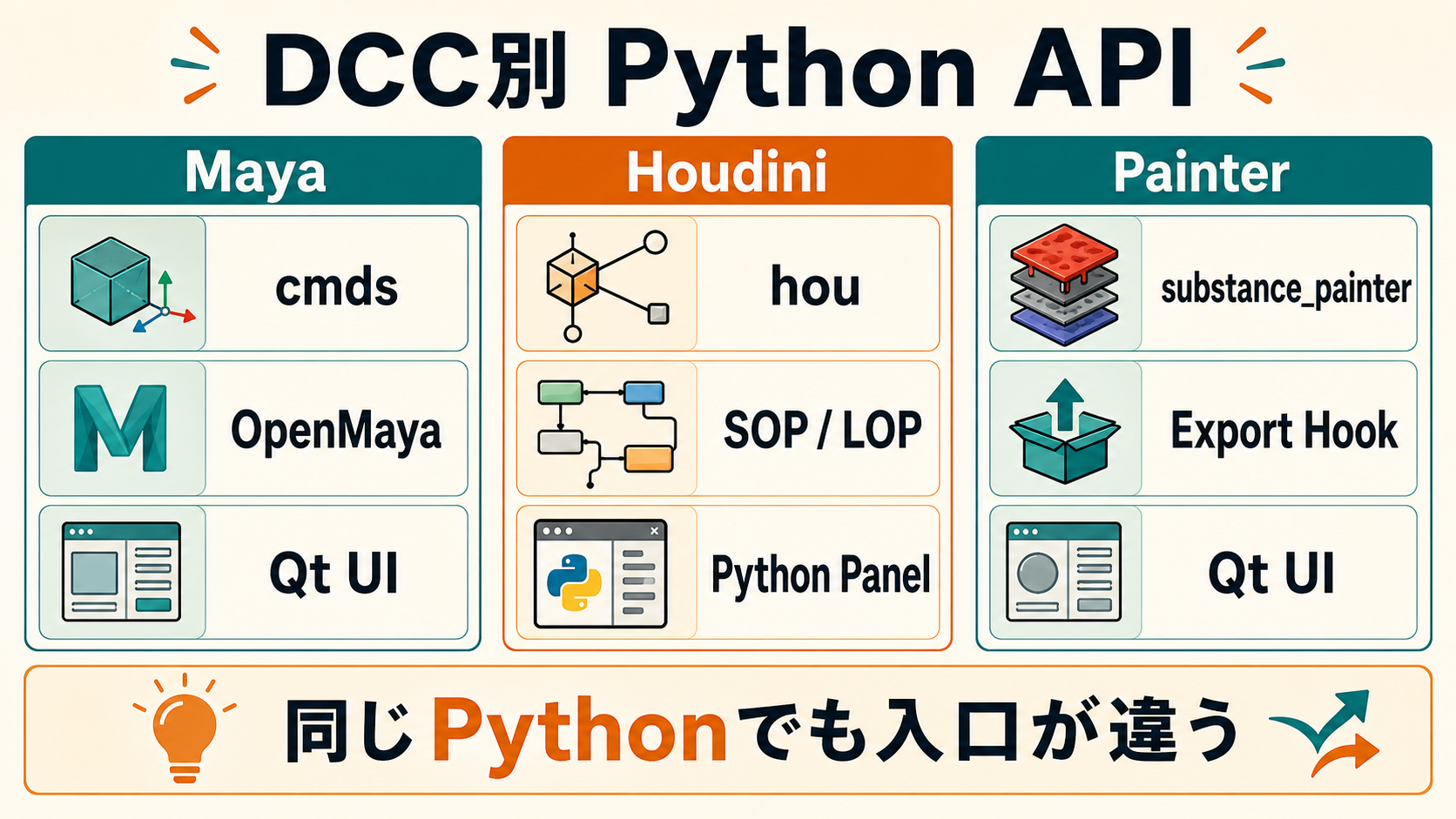
Maya: cmds / pymel / OpenMaya
3層構造で覚えます。
- cmds:MEL コマンドをそのまま Python で呼ぶ命令型 API。例:
cmds.polyCube(w=1, h=1, d=1)。最速で書ける、ドキュメントが多い - pymel:cmds をラップしたオブジェクト指向 API。
obj.translate.set([1,2,3])のように直感的だが、内部で重く、近年は廃止傾向 - OpenMaya(API 2.0):C++ API の Python バインディング。シーン操作・データブロック・MFn ノードなど、深い処理用。プラグイン開発はこちら
実務は cmds を主体に、性能が必要な処理だけ OpenMaya に降ろす、が定石です。pymel は新規採用は避け、既存依存を徐々に剥がしていく方針が無難です。OpenMaya は学習コストが高いものの、数千ノードの一括操作や、デフォーマ・データブロックを直接いじる場面で cmds の数十倍の速度差を生むことがあります。「最後の一押し」用に存在を覚えておくと安心です。
Houdini: hou モジュール
Houdini は Python と VEX が役割分担しています。
- hou モジュール:シーン操作、ノード作成、パラメータ設定など、メタな操作(Python)
- VEX:ジオメトリ要素ごとの並列計算(CHOP / SOP内の Wrangle)
「ノードを動的に組む・自動配置する」は Python、「点ごとに高速計算する」は VEX、と分けます。Solaris(LOP)も hou モジュールから操作できますが、USD ベースなので命名規則は USD 流(Prim パス)に従います。
Substance Painter: substance_painter モジュール
Painter のプラグインは substance_painter モジュールを使います。プラグイン構成は次の最小単位です。
__plugin_init__():プラグイン読込時に呼ばれる初期化__plugin_close__():終了時のクリーンアップsubstance_painter.eventモジュール:保存・テクスチャ書き出しなどのフック
UI拡張は Qt(クロスプラットフォームの GUI フレームワーク。PySide2 / PySide6 はその Python バインディングで、Qt 5系/6系に対応)で書きます。Maya / Houdini と Qt のバージョン違いに注意です。
Python バージョンの分断問題
DCC ごとに同梱 Python バージョンが違います。
| DCC | 同梱 Python |
|---|---|
| Maya 2022〜 | Python 3.x |
| Maya 2020 以前 | Python 2.7 + 3.7 併存 |
| Houdini 19.5〜 | Python 3.9 / 3.10 |
| Substance Painter 8〜 | Python 3.7 |
| Blender 4.x | Python 3.11 |
 夕宮たいだ
夕宮たいだここ、ほんと事故るからね! Python バージョンの取り違えで、import できない・動かない、よくあるんだぁ。バージョンマトリクス、最初に1枚作っといてねぇ。
複数バージョンを跨ぐコードを書くなら、from __future__ import annotations の活用、typing.Optional でなく Union[..., None] の使用、新しい f-string 構文の限定使用など、互換性ガイドラインの整備が必要です。
ていねいに整理するねぇ。同じ「Python」でも、DCC によって 3.7 / 3.9 / 3.11 と違うことがあるんだよぉ。
3. 共通化のパターン:Standalone・GUI・Hook
ひとことで:処理の「主導権」が誰にあるかで、3パターンに分かれます。
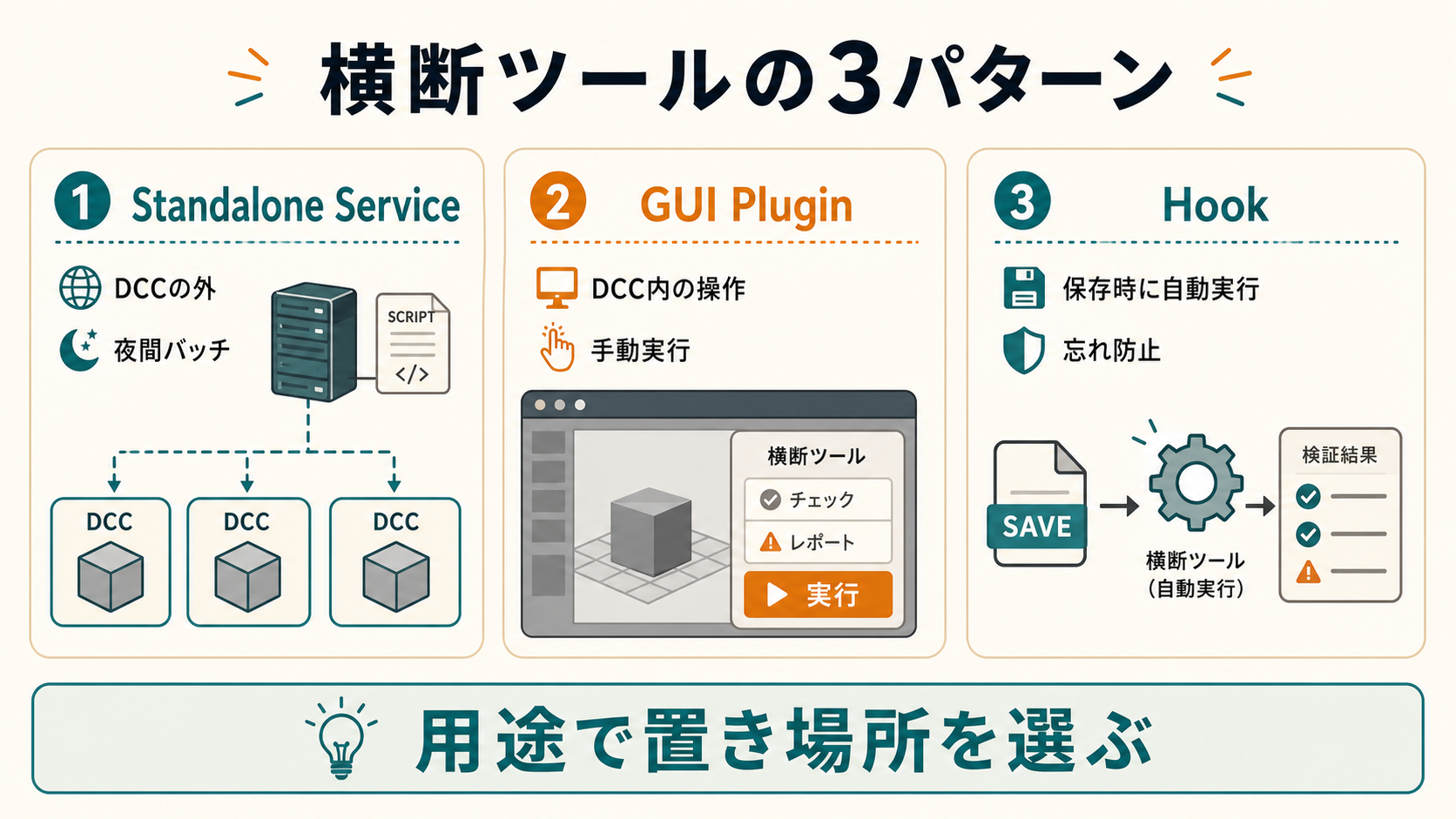
Standalone Service
DCC の 外 で動く独立したスクリプトやサービス。DCC を subprocess 経由で起動し、結果を受け取ります。
- メリット:DCC のクラッシュに巻き込まれない、CI に乗せやすい、複数 DCC を順番に叩ける
- デメリット:DCC 内部の対話的状態にアクセスしづらい、起動オーバーヘッドが大きい
- 向く用途:夜間バッチ、ビルドサーバー、QA バリデーター
GUI Plugin
DCC 内 に常駐するパネル。ユーザーがボタンを押して呼び出します。
- メリット:DCC 内部状態に即アクセス、対話的な編集と相性◎
- デメリット:DCC ごとに UI 移植が必要、テストが難しい
- 向く用途:アーティスト向けユーティリティ、リネームツール、レイヤー切り替え
Hook
DCC の イベント に紐づいて自動実行されるスクリプト。「保存時」「エクスポート時」「シーン読込時」などに発火します。
- メリット:人間の忘れを防ぐ、品質ゲートとして機能
- デメリット:エラー時の挙動設計が難しい、止めると全員に影響
- 向く用途:命名チェック、メタデータ自動付与、ベイク前バリデーション
 夕宮たいだ
夕宮たいだほえ〜、3パターンで分類できるんだぁ。「外」「中常駐」「イベント」って整理すると、迷わないよぉ。
実プロジェクトでは、3パターンを組み合わせます。「Hook で保存時にバリデーションを走らせ、エラーは Standalone Service に委譲して詳細レポート → GUI で結果を表示」のような流れが典型です。
4. データ受け渡し:subprocess・IPC・REST
ひとことで:規模と疎結合度に応じて、ファイル経由・プロセス間・ネットワークから選びます。
DCC 間や Standalone サービスとの通信は、3方式が定番です。
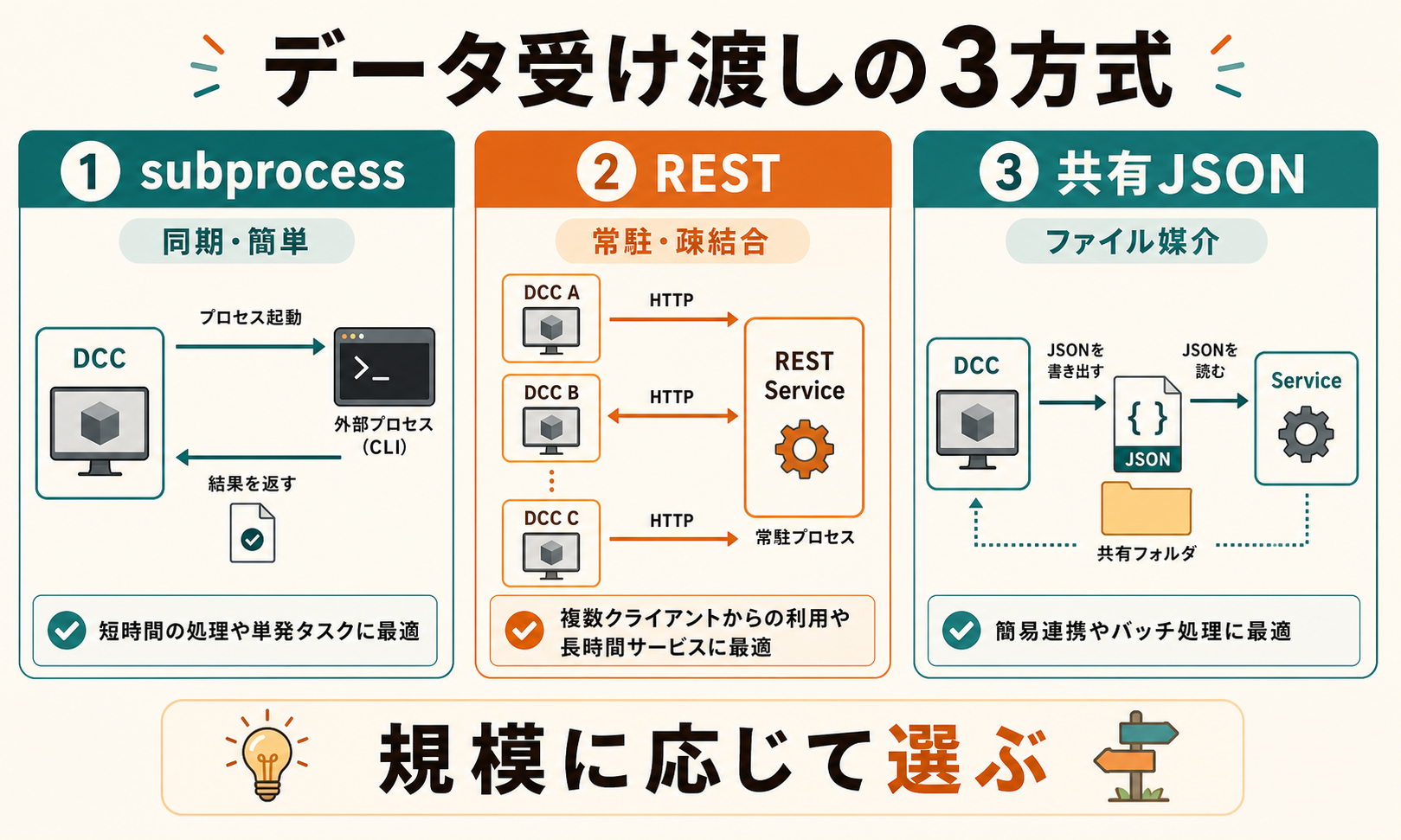
subprocess(プロセス間、同期)
Python subprocess でコマンドを起動し、標準出力で結果を受け取る最もシンプルな方式です。
import subprocess
result = subprocess.run(
["mayapy", "validate.py", "asset.ma"],
capture_output=True, text=True
)
print(result.stdout)DCC をバッチモードで起動し、結果をパースします。小規模・シンプルな処理に向きます。
JSON-RPC や REST(ネットワーク、疎結合)
Standalone Service を HTTP サーバーとして常駐させ、DCC 側から API 呼び出しを行います。
- メリット:複数 DCC から共通サービスに繋がる、言語混在も可能
- デメリット:ポート管理、デプロイ、認証など運用コストが増える
- 向く用途:複数アーティストが共有するアセットメタデータDB、横断 QA サーバー
共有ディレクトリ+JSON(ファイル媒介、疎結合)
DCC は JSON を吐き、別ツールがそれを拾う、ファイルベースのゆるい連携です。
- メリット:実装が単純、デバッグが楽(ファイルを見ればわかる)
- デメリット:リアルタイム性なし、ロック競合の考慮が必要
- 向く用途:書き出し → 後処理パイプ、ビルドサーバーへのジョブ投入
 夕宮たいだ
夕宮たいだぁぅ……どれもメリットとデメリットがあるんだぁ。最初は subprocess、規模が増えたら JSON-RPC、と段階で切り替えるといいよぉ。気をつけてねぇ。
5. テスト・運用:QA/ロギング/設定管理
ひとことで:パイプラインコードもプロダクトです。テスト・ログ・設定の最低ラインを設計します。
パッケージ管理
venvまたはpoetryで各プロジェクトの依存を分離- DCC 同梱 Python と外部 venv の 依存衝突 に注意(Maya 同梱 numpy と venv の numpy がぶつかる)
- パイプライン用ライブラリは社内 PyPI または Git URL でバージョン管理
ロギング
printではなくloggingモジュールを使う- レベル設計:
DEBUG(開発)/INFO(通常)/WARNING(注意)/ERROR(失敗) - ファイル出力+ローテーション(
RotatingFileHandler)で過去ログを残す - DCC 内のログと Standalone サービスのログを 同じフォーマット に揃える
設定管理
- ハードコードを避け、設定は YAML / TOML / JSON に切り出す
- ロケーション戦略:プロジェクトルート → ユーザーホーム → 環境変数の優先順
- 環境別設定(dev / staging / prod)を分けられる構造に
テスト・CI
pytest(Python の標準的なテストフレームワーク)でユニットテスト(DCC を起動しないモジュールに限定)- DCC 統合テストは
mayapy(Maya 同梱の GUI なし Python 実行ファイル) /hython(Houdini 同梱の GUI なし Python 実行ファイル)でバッチ実行 pre-commit(コミット前に自動チェックを走らせるツール)で lint(ruff=Rust 製の高速 Python lint&formatter。文法・スタイル違反を検出)・型チェック(mypy=Python の静的型検査ツール)を自動化- GitHub Actions(GitHub 内蔵の CI サービス)/ Jenkins(オープンソースの CI サーバ)などで CI を回す
「DCC を起動しないテスト」と「DCC を起動するテスト」を分けて、前者は CI で頻繁に回し、後者は1日数回のバッチで回すのが現実的です。DCC を起動するテストは1回数十秒〜数分かかるため、すべての PR で全件流すと開発サイクルが破綻します。「軽いテスト=即時、重いテスト=夜間」の二段構えがチーム規模が大きくなるほど効いてきます。
エラー時の挙動設計
特に Hook と Standalone Service では、失敗時にどう振る舞うか を最初に決めておきます。
- Hook:保存やエクスポート自体は止めず、警告だけ出すのか、エラーで停止するのか
- Standalone Service:HTTP 200 で警告内容を返すのか、5xx で例外を返すのか
- GUI:例外ダイアログを出すのか、ログだけに残してユーザーには成功と見せるのか
これを設計せずにリリースすると、「保存できなくなった」「FBX 出力が突然失敗するようになった」のような アーティスト全員のブロッカー を起こしかねません。
6. 簡易事例:マルチDCCバリデーター
ひとことで:FBX エクスポート前にメッシュ・命名・UV・ヒストリーを横断チェックする仕組みです。
実例として「FBX 書き出し前バリデーター」を考えます。要件は次のとおりです。
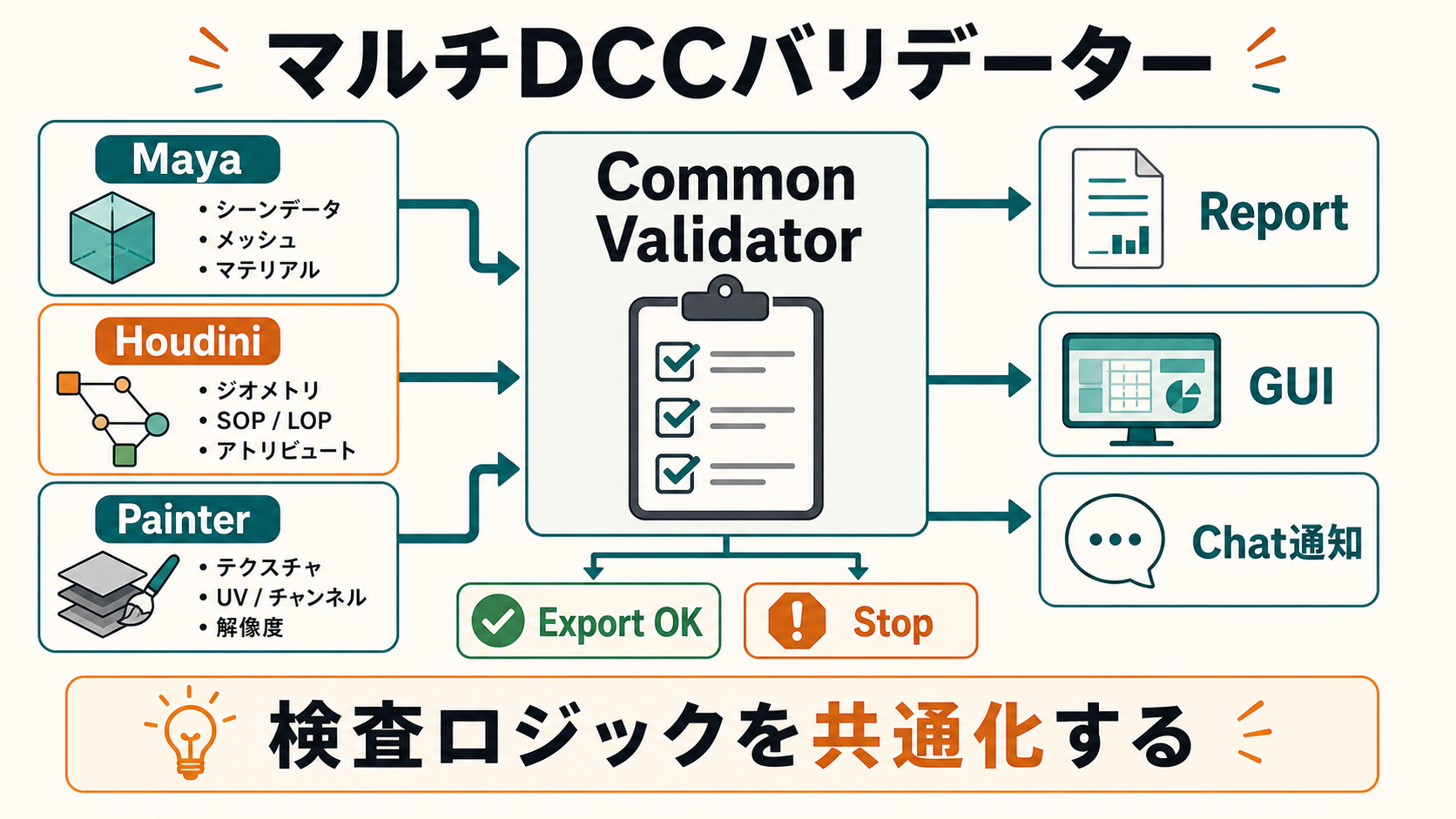
1. Maya 上で「Export FBX」ボタン代わりに、まずバリデーターを呼ぶ 2. バリデーターは命名・スムージング・UV・ヒストリー・トランスフォームをチェック 3. 結果は GUI で表示。警告のみなら続行可、エラーなら書き出し中止 4. 書き出し OK の場合のみ、FBX 出力を実行 5. 書き出した FBX を Standalone Service に投げ、Painter ベイク用の前処理を起動
実装の骨子
- Maya 内:
PySide2で簡易ダイアログ、内部でcmdsを叩いて検査 - 共通検査ロジック:別パッケージ(
pipelib.validators)に切り出し、Maya / Houdini / 単体テストで再利用 - Standalone Service:
fastapi(型ヒントベースの軽量Web API フレームワーク)+uvicorn(fastapi を動かす ASGI サーバ)で常駐、バリデーター結果を受け取り次の処理をトリガー - ログ:
loggingでpipelib.log/{date}/{user}.logに出力 - 設定:
pipelib/config/project.yamlから閾値(例:UV 島の最大数)を読む
 夕宮たいだ
夕宮たいだこれ作れたら強いんだぁ。アーティストの「気合いで確認」をなくせるって、ほんと尊いんだよぉ。ふふ、便利でしょ?
最初は1プロジェクトの1チェック(命名規則だけ)から始め、運用しながら追加していくのが現実的です。完璧を目指して全機能を一気に実装しようとすると、リリース前に頓挫します。
段階的に育てる順番
実プロジェクトに導入する場合の優先順は次のとおりです。
1. 命名規則チェック:正規表現1本で済む、効果が即体感できる 2. トランスフォーム凍結チェック:Freeze 忘れを検出 3. ヒストリー有無チェック:Delete History 忘れを検出 4. UV島数・はみ出しチェック:CR-03 の知識を活かす 5. スムージング設定チェック:CR-04 のハードエッジ規約と整合 6. エクスポート前の自動 FBX 保存:人間の判断を不要にする
各ステップを「アーティスト全員に行き渡って、目に見える効果が出てから」次に進むのが、定着の鉄則です。
7. ハンズオン演習
ひとことで:自プロジェクトの DCC で「保存時の命名チェック」Hook を1つ書きましょう。
最小ハンズオンの手順です。
1. DCC(Maya 推奨)の起動時スクリプトに、保存イベントへのコールバックを登録 2. コールバックは現在のシーン名を取得し、命名規則正規表現に照合 3. 違反していたらダイアログ警告、ログに記録 4. テストとして、規則違反のファイル名で保存して警告が出ることを確認
import maya.cmds as cmds
import re, logging
logger = logging.getLogger("pipeline")
def on_save():
scene = cmds.file(q=True, sn=True, shortName=True)
if not re.match(r"^[A-Z][a-zA-Z0-9_]+\.ma$", scene):
cmds.warning(f"Naming violation: {scene}")
logger.warning(f"Naming violation: {scene}")
cmds.scriptJob(event=["SceneSaved", on_save])20行程度ですが、Hook の本質(自動化・忘れ防止・ログ)を1ファイルで体感できます。これに「UV 島数チェック」「ヒストリー有無チェック」を追加していくと、自然にバリデーター本体に育ちます。
8. チェックリスト
ひとことで:パイプライン設計時のセルフチェック項目です。
- [ ] 各 DCC の Python バージョンを把握している
- [ ] 設計パターン(Standalone / GUI / Hook)の使い分け基準を持っている
- [ ] データ受け渡し方式(subprocess / REST / ファイル)を規模で選べる
- [ ]
loggingでレベル設計をして、printを使っていない - [ ] 設定をハードコードせず、YAML / TOML / JSON に切り出している
- [ ] DCC 統合テストの実行手段(
mayapy/hythonバッチ)がある - [ ] CI で lint / 型チェック / テストが回っている
9. よくある間違い・トラブルシュート
ひとことで:Python バージョン取り違え・依存衝突・設定散乱・ログ未整備、の4つが定番です。
Python バージョン取り違え
「Maya 2022 で動くコードが Houdini で動かない」「f-string の = 構文が古い Python で使えない」など。CI で複数バージョンの動作を保証するか、互換ガイドラインを文書化します。tox や nox で複数バージョン並列実行が定石です。
DCC 内ライブラリと外部 venv の衝突
Maya 同梱 numpy と venv の numpy がバージョン違いで衝突、PYTHONPATH の優先順で挙動が変わる、という事故です。DCC 同梱 Python は触らず、外部 venv は別プロセスで動かす のが安全です。GUI 拡張だけ DCC 内、重いロジックは Standalone に寄せる設計にします。
設定ファイルが散乱
スクリプトごと・ユーザーごとに設定が散ると、再現困難なバグが頻発します。ロケーション優先順位を明文化 し、pipelib.config.load_config() のような単一の読込関数で吸収します。
ログが未整備
エラーが出ても情報が残らず、「再現待ち」になる悲しい状態。print のままにせず、logging のレベルとフォーマットを統一します。Standalone・DCC 内・CI で同じ形式に揃えると、横断検索が可能になります。
夕宮たいだふぁ……パイプラインの話、ちょっと長かったかなぁ。でも、ここを設計できると現場が一気に楽になるんだよぉ。次は QA や、各 DCC 実機編に進めるよ〜。
10. 次に読む記事
ひとことで:パイプライン設計を、命名・QA・各 DCC 実装に繋げていきましょう。
- CR-09 アセット命名・バージョン規則:パイプラインの土台になる命名・バージョン規約
- CR-14 レビュー・QAの設計:バリデーター・レビューフローの設計論
- CR-08 USD入門:USD Python API による横断パイプラインの背景
- MY-A07 OpenMaya API:Maya 深い処理の実装編(公開準備中)
- HD-A08 Python in Houdini:Houdini Python の応用(公開準備中)
- SP-A04 Pythonによる自動化(Painter):Painter プラグインの実装編(公開準備中)
—







